UE渲染师Dyomin:做次世代手游 可以用好这项技能
原标题:UE渲染师Dyomin:做次世代手游 可以用好这项技能
2020虚幻引擎技术开放日上,来自虚幻引擎移动端团队的负责人Jack Porte和团队的渲染工程师Dmitriy Dyomin,为大家分享了虚幻引擎4对于移动端的更新内容。

我们已经分享了Jack Porte的演讲内容了,接下来,Dmitriy Dyomin会详细讲述虚幻引擎的图像渲染技术, 尤其是移动端的延迟着色。
以下为演讲内容(有节选):
大家好!我是Dmitriy Dyomin,我在Epic Games工作,主要任务是改善渲染效果以及一些移动端的综合功能。今天我要讲的是移动平台的延迟着色。
延迟着色有前向着色难以比拟的高效优点
我们先来介绍 虚幻引擎移动端渲染的现状。
在移动平台上的默认情况下,我们在使用渲染器上会用到一种简单的前向着色技术,它针对移动端GPU,是经过优化后有完整功能的电脑端渲染器,你可以在移动端启用电脑端渲染器的支持,它就在引擎中“平台”的“项目设置”里。

当然,电脑端渲染器也可以和延迟着色功能一起使用,不过电脑端渲染器对移动端来说难以承受,并且不能妥善利用移动端GPU的架构,保证不了延迟着色功能。
所以今天我要介绍一下我们的新延迟着色功能,它针对移动端GPU进行过优化。启用它的方法是在你的项目中添加r.Mobile.ShadingPath=/到DefaultEngine.ini。
我们来看看延迟着色的优点,以及它在移动端GPU上是如何高效实现的。
首先来了解前向着色。它的优点以及局限是使用前向着色时,你可以通过单个pass渲染完场景,这对移动端GPU来说非常棒,因为它不需要大量内存带宽。
不过,前向着色目前没有很好的支持光照贴花的方法,要想完全支持它,就必须具备某种D缓冲区,还需要让场景具备全深度的预渲染。而延迟着色,可以避免这一缺陷。
延迟着色的工作逻辑是,首先,它将所有对象和像素材质数据都渲染为多种纹理,这称为G缓冲区。第二,它渲染光照体积在渲染光照体积时,着色器会从G缓冲区读取数据,并计算最终像素颜色。
这样延迟着色就具备了一个主要优点就是,材质和光照的计算是完全相互独立的。这意味着我们不需要将光照代码包含在材质代码中,我们也不需要大部分的阴影变体,那是前向着色才需要的。

同时也让过度绘制的性能消耗大幅减少,因为在渲染到G缓冲区时,我们执行的是材质代码而并不会执行光照代码,只有在结尾的时候我们才会处理光照。我们只会在最后将光照应用于可见的像素。
延迟着色在移动端的性能演示
现在我们来了解一下为什么延迟着色在移动端GPU上的操作以及它更好的性能。
移动端GPU大多基于图块,这意味着它们会将帧缓冲区分布到名为图块的更小区块上,然后依次渲染这些图块,且只将最终结果存储到系统内存中,所有图块的渲染都消耗很小,不会将中间结果存入系统内存。这有助于减少内存带宽开销。

但在延迟着色时,你必须为每个tile做两个pass,因此你必须存储中间数据,也就是G缓冲区,将它存入系统内存,然后第二pass会把它采样为纹理并应用光照,从而计算最终像素颜色。
在GPU和系统内存之间,用这种方法移动G缓冲区数据并不高效,我们想要实现的是在单个pass中实现多pass渲染,并且不将中间数据存入系统内存,这样的话 就在保持单个pass渲染的优点的同时,保持了材质和光照数据的相互独立。
为此,负责应用光照的着色器,需要设法获取G缓冲区数据,并将其采样为纹理。
我用的是Metal、Android Vulkan和Android OpenGL,它们都能做到这点,但它们各自的做法都略有不同。
Vulkan是一种现代化的图形API,大部分现代安卓设备都支持它,这是一种非常显性的API,因为它的接口考虑到了基于图块的GPU的运行。

Vulkan渲染过程被分为多个子pass,这些子pass通常有着各自要执行的任务。不过我们可以将多个子pass融合为一个pass,如果可行的话意味着我们可以用较小的消耗保持G缓冲区,而无需把它移动到系统内存,这能节省大量外部内存带宽,这对移动端非常重要。
关于移动端的延迟着色,我们最终会得到三个子pass:第一个是G缓冲区渲染子pass,它会写入G缓冲区,并填充深度附件;第二个是贴花子pass,我们会向G缓冲区写入,但深度是只读的,不过深度还是可以被获取;最后的子pass我们只会向场景颜色写入,并获取G缓冲区和深度。在这里将所有光照都处理完后,我们会利用前向着色来渲染半透明。最终,一切大功告成。
强调一下,我们总共有三个子pass,它们都被融合为一个pass。第二个子pass往往是空的,场景里面并不总是有贴花的,但我们还是要把它做出来。这是为了避免出现两种不同的渲染pass配置,导致渲染pass配置会被烘培进管线状态对象。

Metal的原理与之相似,处理要简单的多。因为在iOS版的Metal上,你无需在渲染pass中分清具体的子pass,以及它们之间的依赖性。在Metal的着色语言中,你可以宣称某些附件为某个碎片着色器的输入。然后,它们就有了G缓冲区数据。利用这个机制,你可以实现程序的混合,也可以实现不同的着色功能。

我刚才说了Android Vulkan和iOS Metal,但Android OpenGL是怎样的呢?

使用Gl拓展项时,是可以实现高效的延迟着色的,有两种拓展项可以低消耗地访问芯片上的像素数据。
首先是像素本地存储,支持它的有Mali GPU以及 ImgTech PowerVR GPU。但Adreno GPU不支持它。
第二个拓展项是着色器帧缓冲区读取,它拥有其它Adreno的支持,但Mali GPU不完全支持它。在Mali上,你只能用这个帧缓冲区拓展项来读取单个附件的数据。所以我们必须针对每种GPU做不同的延迟着色支持,我们可以在运行时为着色器打补丁,从而实现这点。这取决于设备的GPU。
我们已经有了可用的原型,它兼容像素本地存储以及帧缓冲区拓展项。我们仍在反复雕琢一些细节,让它在最新版本中完全发挥作用。
有了延迟着色,我们现在就能支持更高质量的反射,可以混合影响到每个像素的所有反射捕捉,并正确地与非静态天空光照反射进行混合。
延迟着色,进一步提升光照渲染质量
现在我们来聊一聊我们做过的一些 光照渲染方面的优化。
当我们采用平行光时,就会有FullscreenQuad。FullScreenQuad会计算屏幕上每个像素的光照,但我们并不需要为每个采用无光照着色模型的像素应用着色。那么在我们渲染到G缓冲区,渲染无光照着色模型时,我们能做些什么呢?
我们可以 写入到无光照像素的模板。在这么做的时候,应用光照我们可以配置模板测试,还可以过滤掉所有无光照像素。这是一种很棒的优化,尤其对于有室外环境的游戏来说,它们有天空场景,往往会使用无光照着色模型。天空往往占据一半左右的屏幕,所以你就可以抛弃一半的像素。

另一项优化 在渲染体积时,可以被应用在局部光照渲染上。例如对于聚光灯光源,我们会试着着色所有在体积内的可见像素,但我们只需要为那些与光照体积相交的几何体上的像素着色就行了。

在这例子中 可以看到光照体积实际上只照亮了地板上的一些像素和地板上的盒子。有一种旧算法,它使用双pass技术会调用未受到光照体积影响的像素,所以我们就会把每个光照体积渲染两次。
在第一个pass我们并不写入到颜色缓冲区,我们只渲染体积的正面。我们在深度测试失败时更新模板,在第二个pass 我们渲染同样的体积,但采用光照着色器只渲染背面。
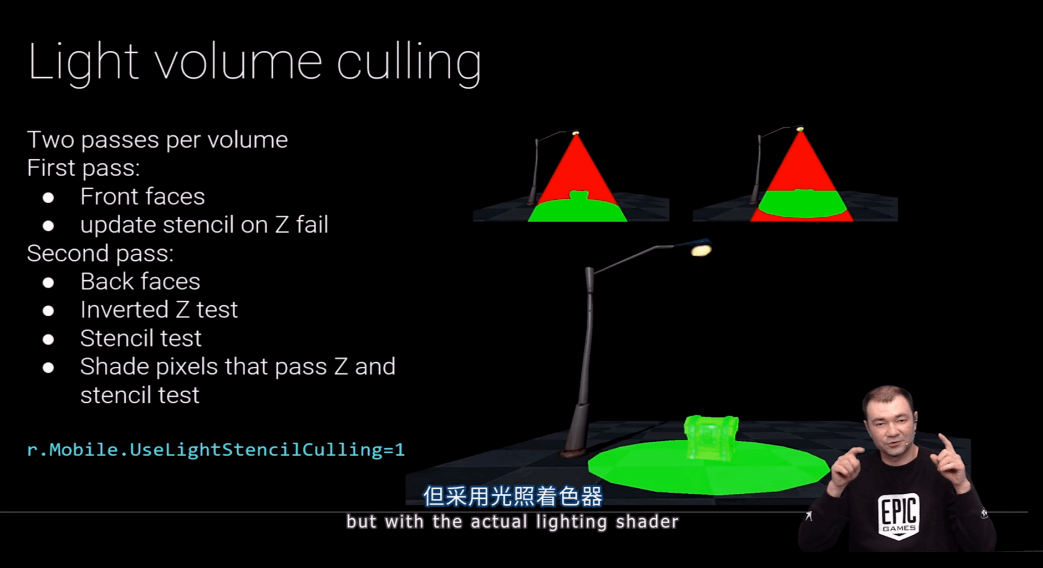
我们做反向的深度测试,也只对同时通过深度测试和模板测试的像素着色。使用这种算法后,你可以仅计算与光照体积相交的像素。不过这会增添额外的绘制调用,以及各绘制调用之间的状态切换。
但在我们的测试中,这项优化在大部分移动端的情况下仍然是有益的。尤其是你的场景中并没有很多局部光源的情况,因此在你使用延迟着色时,这项优化是默认启用的。但你可以随时禁用它,只要使用r.Mobile.UselightStencilCulling即可。
我们依次渲染各个局部光照,按照其贡献调整最终场景颜色。但当屏幕上有许多局部光源时,为每个光源进行绘制调用,会消耗大量性能。我觉得这个转折点大概是个可见绘制调用个可见光源,所以如果你使用模板裁剪优化的话,就必须调用。
你会有个只为了渲染光源的大概绘制调用,当存在大量重叠光源时,性能消耗也会很大,因为这要消耗大量GPU算力。不过可以采用的办法是,将视野分散到各个图块并在帧开始时运行一个计算任务,由此生成光源列表。它们会影响每个集群,在渲染平行光时,我们查看光源列表,可以将影响到当前像素的所有局部光源融为一体。这意味着我们可以在一次绘制调用中应用所有局部光源的光照。
用来裁剪局部光源的优化,在延迟着色时,无法与集群并用。这种集群延迟着色是被默认禁用的,所以你只能在需要大量可见光源时才能开启它。
关于移动端延迟着色的性能表现,我们尚未完全探明。但在更早期的测试中,它在GPU上的速度比前向着色慢了5%。但我们可以使用了一些测量工具来查看数据。
结果表明,延迟着色在GPU上的计算开销要少得多,使用的内存带宽也少得多,所以它读写的内存更少。
我们计划在《堡垒之夜》移动版上,在某些情况下来启用它,测试延迟着色。
结语:
相比前向着色,延迟着色可能是更好的选择。移动端延迟着色是一项新功能,它带有实验性质,所以对我们来说,它还有很大改进空间。
首先就是优化。我说过,它目前采用位的G缓冲区,我觉得我们可以把它降低到位。目前它只支持默认有光照的着色模型,以及无光照的。所以我们要为它添加更多着色模型,至少要有次表面着色和透明涂层。但要添加这些着色模型,我们就需要在G缓冲区内增加额外的空间,所以我们要让它们变得更精简。
有了延迟着色,就能够有效地渲染光照函数,以及IES光照配置文件。所以我们也添加了IES光照配置文件。
还有,目前移动端前向渲染可以适用于聚光灯的动态阴影,但延迟渲染做不到。因此我们也需要添加前向渲染。
我们还可以添加屏幕空间反射,用于抗锯齿的解决方案我们也要添加,以应付高质量时域抗锯齿方面的工作。





